
What is AI?
What is AI?
ok so verrrry broad terms about what AI is…
First, I have a short-ish version of what’s going on.
Then a longer version if you want a rough idea of how it’s actually working (explained by someone who scraped by in their undergrad degree lol)
the short version
“AI” is usually used to refer to “LLMs” - large language models. It’s a big mathematical model that takes in a large amount of text, converts it to “tokens”, and uses that to predict a result, also as text. (look there’s also images and now video butttt… it kinda does the same thing under the hood. it’s all “tokens”)
Each time an LLM is run, it works on a huge amount of calculations based on probabilities. These probabilities are worked out using training. This is a mostly automatic process where you have some input data which you know the result for, and you keep running the model over and over again and changing values until the results are close to what you expect.
Training and its energy impact
This training uses a lot of energy and data. Latest models are scouring the entire Internet, Wikipedia, textbooks, you name it, to find example data that they can use to train the models to guess the word that comes next. GPUs work quite well for this. So tech companies have been buying them all up…
Are they giving attribution or asking for permission…? Er… no. Usually not.
Running the model each time, even once the training is done, still requires loads of data, storage and energy. The environmental impact of the data usage means fossil fuel power plants are being brought back online. Tech companies are building miniature nuclear power plants just to keep up with the energy demand (small modular reactors. Data centers are stealing polluting water from surrounding land to keep their servers cool. We are going backwards on global emissions goals.
How many "r"s in “strawberry”?
Now remember I mentioned this is all based on probabilities? You betcha. This means that the output is never guaranteed. It makes mistakes, or “hallucinates”. The same input doesn’t always return the same thing. This means that LLM models can be unpredictable and work in unexpected ways. E.g., asking a model to add a list of numbers. Earlier models would convert the numbers to tokens, and because it sees something like “add these numbers” it will try to predict the output based on what it’s previously seen to come up next. This is why some models can’t even count the number of "r"s in “strawberry”.
An example. Asking GPT-4o to add up numbers.
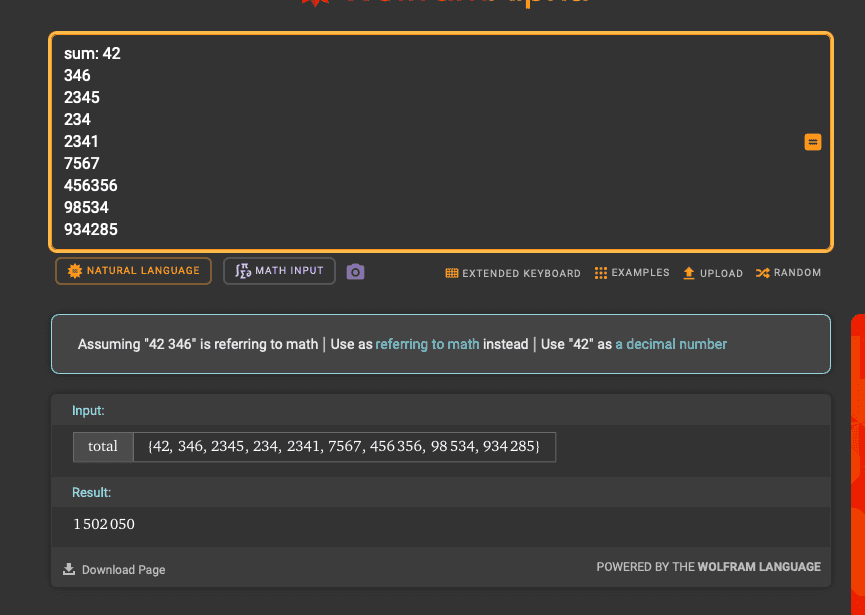
Above: The correct answer, produced by Wolfram Alpha
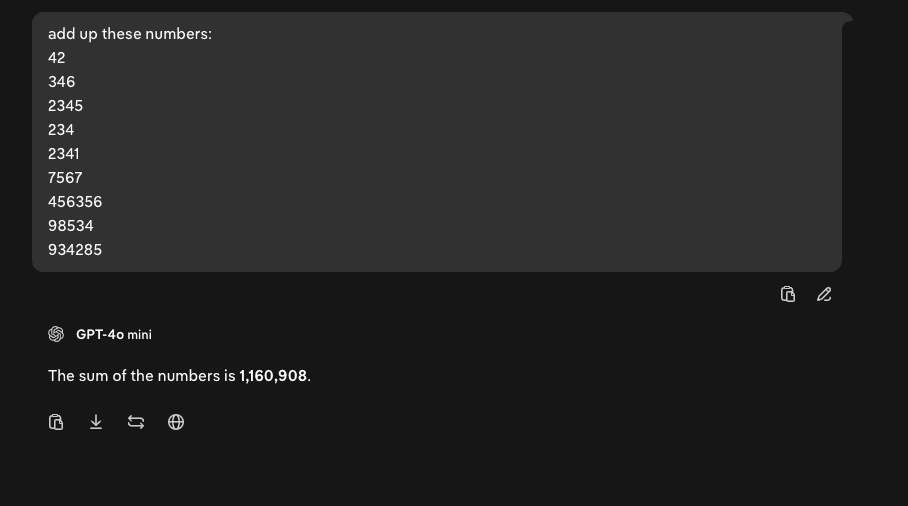
Above: GPT-4o mini’s attempt.
Other models will predict that, say, there’s a list of numbers to add up, and then call upon a program to sum them before giving it back to the model to return as an answer, for instance. This is how a lot of modern LLMs now work, they are able to access a range of tools and programs to work in multiple steps to predict an answer. This is why, e.g. when you run Notion AI, you can see it print out a load of information as this process unfolds. It’s often known as “multi-stage reasoning”.
Prompts and prompt injection
A “prompt” is another word for the text input someone gives to an LLM. It can be a question, instructions and can get quite detailed.
Prompts can often be saved, used and shared as a way of encouraging an LLM to work in a certain way or provide a certain type of answer. You often hear these referred to as “skills”, “gems”, “custom GPTs”, that kind of thing. For instance, you might have one that says something like source:
“ You are an AI agent working for an ecommerce company as a customer service representative. Your role is to help customers with order tracking, shipping and delivery concerns, and refund requests in line with our company policies. CHAT HISTORY customer: blah blah blah blah? ”
Everything is fed as input into the LLM in the same way and converted into tokens the same. The chat history and the prompt used to try and control the behaviour of the model. It’s all treated the same, although by trying to separate separate bits of information like humans do in their writing (horizontal lines, headings, spaces) can try to influence these. Using strong, imperative language and even ALL CAPS can try to steer the model further into the behaviour the author wants.
Since the chat history and the original prompt are both treated the same way, does that mean the person sending messages to the customer support could use the same techniques to get the model to do what they want, even if the author didn’t want this?
…yeeeessss.
This is called prompt injection and it’s basically unfixable because of how these models operate (source). It’s been used to send malicious calendar invites to steal private information with Gemini. It’s an incredibly difficult problem!
Other bits
So there’s also the idea that because LLMs are trained on publicly available data, and more data online is being produced by LLMs, there’s this weird phenomenon where these models are training on themselves and converging towards “average” results. The Claude Opus 4.6 model has a reduced performance compared to 4.5. Generated images are increasingly becoming streaked with piss yellow because everyone in 2015 was using the X-Pro 2 filter on Instagram. “Model collapse” is something that some people believe to be an inevitability. I mean. People are sharing techniques for trying to get rid of the tint:
But also it means that when LLMs “hallucinate”, these can find their way into articles and blog posts. This finds its way into training data and now these fake statements become reinforced as “facts” according to future LLMs. It’s affecting journalism and resulted in an editor being fired. It’s alarming quite how much of the Internet is now being polluted with lies and slop.
The companies behind LLMs are morally bankrupt and are subsidised heavily by private equity. A recent Forbes article suggests Anthropic could be running up to $5,000 of computing power for a user spending $200… A lot of OpenAI’s funding is reliant on it “achieving AGI” (that’s Artificial General Intelligence, just a buzzword for a model that is smarter than a human) within a certain timeframe and it’s just not getting there. Ed Zitron has a fascinating and long article that dives into the OpenAI financials.
They are complicit in the current wars, despite the press releases. Claude has been used by the department of defence to help select targets for bombing. OpenAI seem to have no qualms about automated killbots (until they were caught). They are evil companies run by evil people.
Ok so that’s kinda about it off the top of my head. Below is a more in-depth explanation of how LLMs work if you’re interested.
(neural networks) what came first…
so like, in computing there’s a thing called a neural network. It’s essentially a program that takes some kind of inputs (like numbers!) and then does a bunch of calculations on them, combining and splitting results multiple times, to get an output (could be a number, a true/false, anything like that).
a lot of those calculations work on probabilities, so like, a certain calculation might have an 80% chance of returning a large value over a smaller one. stuff like that. these probabilities are worked out by taking a bunch of input data where we know the answer we want, and running this model over and over again, tweaking these probabilities each time to get the results closer and closer to those answers. this is what training is!
This happens on a huuuge scale. There’s many different calculations running (1000s to even millions!), a large number of inputs, and results being passed to further layers in the system. you could think of it as bit like this:
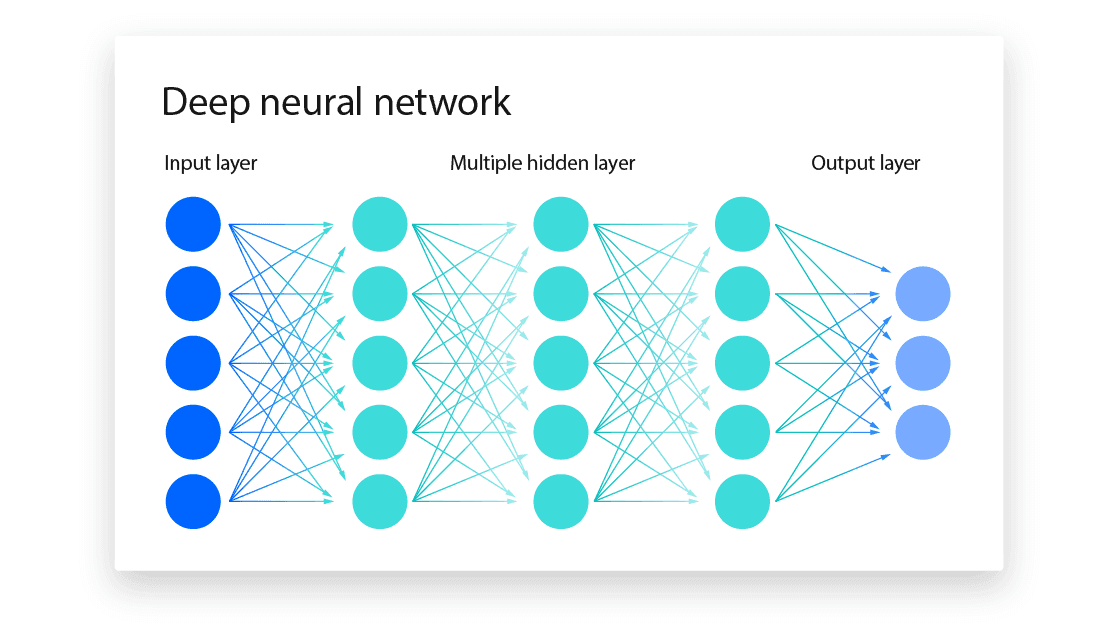
Where each of those circles is some kind of calculation (a neuron!) and each line is some kind of value being passed between it.
Even at a small scale like this, it can be really hard to unpick and work out why one set of inputs leads to an output. The idea is that it works in the same way a brain does. Lots of neurons firing and sending information around to return something that is correct, trained thousands or millions of times with learning data. (“reinforcement learning”).
You can use this for all sorts of cool things! If you imagine images as just a set of pixels with a number that represents its colour, a picture quickly just becomes a list of numbers. Standardise the data, feed it into a network, see if what comes out matches what you expect. Change the probabilities and run it again and see if it gets closer.
anndddd boom. You’ve just created something that can recognise text in images…
this powers pretty much everything in the world. tiktok algorithms, “dynamic pricing” in restaurants, shipping routes, speech to text on your phone. even on iphones, there’s a hidden model that runs on the keyboard that will grow and shrink the keys depending on what you type so you make fewer typus!
ok so now for AI
in the early 2010s, some computer scientists came up with this idea of a “transformer model”. it’s the same kind of thing except that it not only runs multiple networks at the same time, but can share results between them and look back and forwards across the data it receives. it’s now able to remember stuff. this is a “context”, which is a word that comes up so often in AI lol. but it means that one model is able to look at another model to figure out the “context” of what it’s currently looking at.
it makes training a lot easier since there’s no weird loops happening inside the model which for reasons I won’t go into, makes training faster. google dropped a paper at some point called “attention is all you need” and that was the hot shit at the time. this whole idea of being able to figure out the context of a bit of data meant that they got a lot better at being able to ‘understand’ words, language, things. it meant that a model that looks at images can figure out objects and shapes.
“AI” when its talked about at the moment usually refers to a “Large Language Model” or LLM. It’s a model operating on a huge amount of input data - human language. Transformer models are able to take a stream of text and break it down into words and phrases. Older neural networks would just treat it all as a big list of letters. This means that the model is able to simulate “reasoning” across sentences and paragraphs. The “memory” it keeps means that if a “cool cat” was mentioned at the start of the paragraph, it would be “remembered” later on when the LLM is processing a phrase about “the animal”.
This is really how a chatbot like ChatGPT or Gemini works in a basic level! When you send a message, your message and all of the messages in the chat history are turned into a big block of text and sent into an LLM. The LLM will then processes all of the text, turning it into tokens along the way, and then predicting the “most likely” answer.
Images, voice, it all works the same way. Everything is converted to tokens and run through a model and an answer is predicted.
This works okay for things like categorising data, converting speech to text, and picking out themes. It works to a slightly lesser extent for summarising large amounts of text, since its predictions are based on how similar sets of tokens (how similar pieces of writing) in its training were summarised. It can detect common themes or significant points, but can often struggle with prioritising what’s actually important. Because it’s not thinking, it’s predicting based on the data it’s been trained on.
This is why things like Gemini meeting summaries will often focus on small and insignificant things, like “the team discussed their morning commutes” over something like “the team raised concerns about the project’s ethics”. It’s all prediction, and it’s all based on probability. So there’s a chance it will do something unexpected and incorrect, and most often when you’re doing something new.